Over the last year, deep research quietly became one of the most interesting features in modern AI products.
You type a question. A model disappears for a few minutes. Then it comes back with citations, sources, structured analysis, and an answer that feels less like autocomplete and more like actual research.
It is genuinely impressive.
It is also usually hidden behind:
- strict usage limits,
- daily or weekly quotas,
- queue times,
- premium pricing tiers,
- and a black box you are not supposed to look inside.
After hitting those limits enough times, a different question starts to feel more interesting than the research itself:
What would it actually take to build one of these systems myself?
Not a demo. Not a "search five URLs and summarize them" toy. A real system—something that can search broadly, dig deeper, handle messy sources, survive failures, manage costs, keep citations intact, and produce something you would actually trust.
From 30,000 feet, it sounds straightforward.
Up close, it is absolutely not.
Want to first see what the generated reports actually look like? Jump to Sample Reports →
It is easy to assume "deep research" is just:
- Google a thing.
- Open a few tabs.
- Ask an LLM to summarize.
- Ship it.
That works until you try it twice. The third time, you discover the
secret final boss of the internet: reality. Reality comes with popups,
PDFs, infinite scroll, "accept cookies", rate limits, paywalls, 9MB hero
images, and pages that are basically one giant
< div> pretending to be content.
If the goal is to build a real deep-research agent, the system has to start simple and then grow all the defensive features that only show up after getting burned a few times. From 30,000 feet, the problem looks straightforward. Up close, it is absolutely not.
And yes: cost matters. If raw web pages are fed into an LLM like an all-you-can-eat buffet, the wallet does a disappearing act.
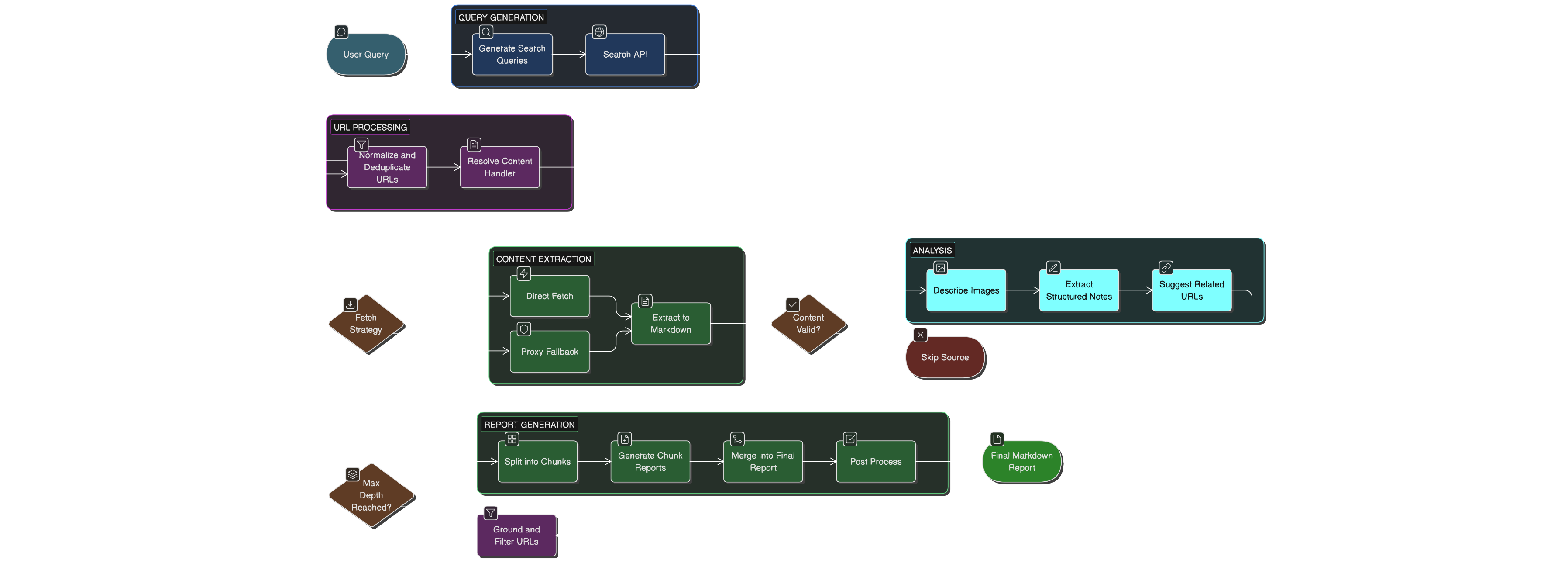
The "Hello World" Research Agent (It’s Cute, But It Lies)
Let’s start with the obvious pipeline:
- Take a user query.
- Use web search to get a handful of URLs.
- Fetch each URL.
- Dump all the text into an LLM prompt.
- Ask for a summary.
In pseudocode:
jsconst query="my topic";
const urls=await search(query);
const pages=await Promise.all(urls.map(fetchText));
const report=await llm(`Summarize this:\n\n${pages.join("\n\n")}`);
This is the research-agent equivalent of claiming cooking skills because toast happened once.
Problem #1"A handful of URLs" is a handful of bias
If you only look at 5 results:
- you get a narrow slice of perspectives
- you miss primary sources
- you accidentally over-weight one loud blog post
- you silently skip the "boring" stuff that’s actually authoritative (standards, docs, filings, datasets)
So the first upgrade is: don’t do one query. Do multiple better queries.
Step 1: Turn One Query Into Several Good Queries
Humans are decent at writing search queries. LLMs can be great at it when constrained properly.
So the agent starts by asking an LLM to generate a small set of high-leverage queries. The intent is coverage:
⌗ Step 1
- broad overview
- recent developments
- primary sources
- critical viewpoints
- history/background
Of course, the internet immediately tries to sabotage you.
Problem #2LLMs occasionally return… interpretive JSON
Sometimes you ask for JSON and you get:
- JSON with trailing commentary
- "almost JSON"
- JSON but inside the wrong code fence
- a heartfelt poem about JSON
This is where you plug-in some JSON repair layer. LLMs do not just break JSON one way; they break it in
ten slightly annoying ways. Using a repair utility that can recover
fenced JSON, strip surrounding prose, normalize Python literals, and fix
low-grade syntax damage is a lot more robust than pretending a plain
JSON.parse(...)is enough.
But, the repair layer might not be able to handle all kinds of damages. And this is why you treat that layer as a "best effort" step: if a clean list cannot be parsed, the system should fall back to the original user query and continue. Research should degrade gracefully, not faceplant because of a curly brace.
Step 2: Search Is Cheap; Fetching and Reading Is Not
Once we have good queries, we search them (through a hosted search provider) and collect URLs.
Problem #3Duplicate URLs, tracking params, and the "www." multiverse
Search results are full of near-duplicates:
-
same page with
utm_*orfbclidtracking garbage appended -
same host with or without
www, a trailing dot, or a default port (:80,:443) -
same URL with reordered query params, mixed-case percent-encoding, or
a
#fragment -
credentials smuggled in (
http: //user:pass@example.com) — useless for dedup, bad for logging
So we normalize and dedupe aggressively before any fetch or cache lookup. This does three things:
- Reduces wasted fetches — no re-crawling the same page via five superficially different URLs.
-
Prevents citation spam — the report won't cite
example.com/article?utm_source=twitterandwww.example.com/article/as separate sources. - Keeps the visited set trustworthy — a hash-map of raw URLs is nearly useless; a hash-map of normalized URLs is an actual dedup layer.
The normalization pipeline, we built, does following, in order:
-
Whitelist
http/https, reject everything else - Strip credentials, fragment, and default ports
- Lowercase hostname, strip
www.and trailing dot -
Delete tracking params by exact name and prefix pattern
(
utm_,fbclid,_hsenc, etc.) - Sort remaining query params for stable canonical form
- Collapse double slashes in path, strip trailing slash
We also maintain "already visited" sets for both queries and URLs. A deep-research agent without memory is just a goldfish with an API key — it'll refetch the same Reuters article six times and call it thoroughness.
Step 3: Fetch Pages… But Don’t Trust Them
Now we try to fetch each URL and extract usable text.
This is the point where naive systems go to die, because "fetch the page" is not one problem. It’s a bag of problems wearing a trench coat.
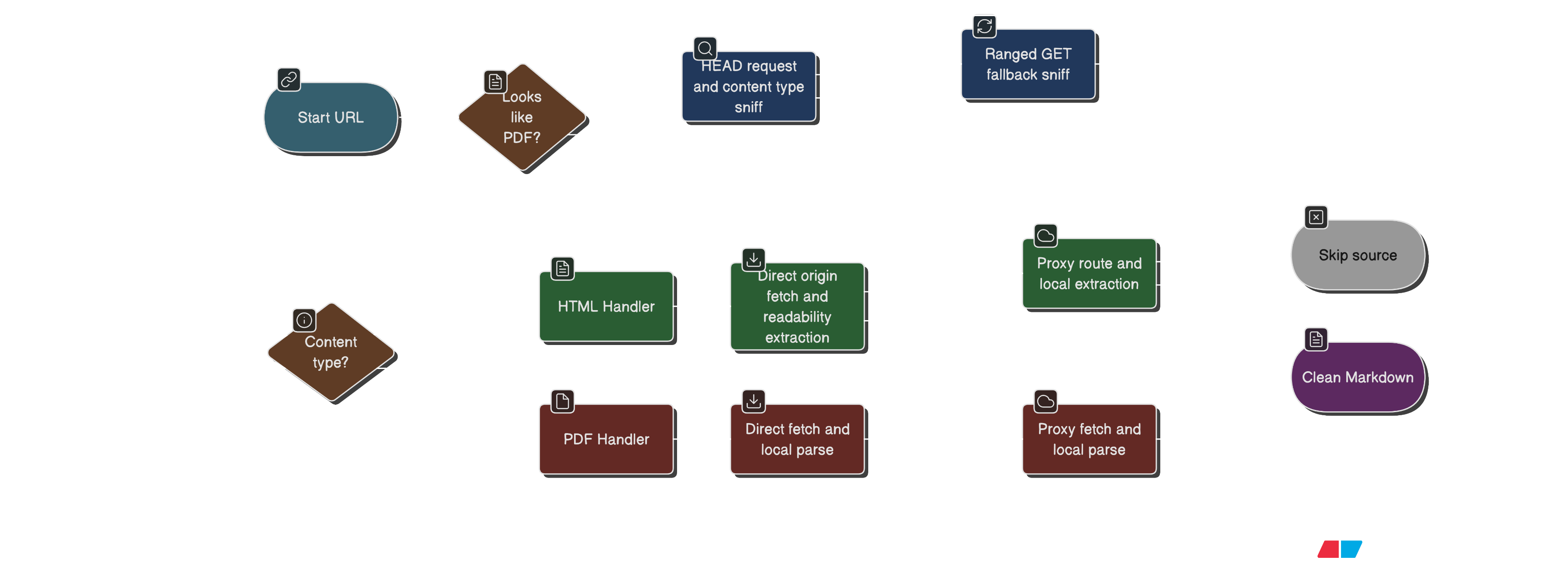
Problem #4Not every URL is HTML
Some URLs are PDFs. Some are HTML. Some are "HTML" that is actually an
error page politely wearing a 200 OK badge.
So the agent resolves a content handler per URL:
- If the URL looks like a PDF, treat it as PDF.
- Otherwise, sniff content type (conservatively) and decide.
- If sniffing is inconclusive, default to HTML.
The content-type sniffing is intentionally cautious: it tries
HEAD, and if that’s blocked or unhelpful, it uses a minimal
ranged GET (fetching the tiniest sliver possible). This is
faster and reduces bandwidth, and it also avoids downloading a whole
novel just to learn the cover says "PDF".
Problem #5HTML is massive, noisy, and allergic to being summarized
Even when you get HTML successfully, you can’t just feed it to an LLM:
- it’s huge
- it contains nav bars, cookie banners, footers, sidebars, "subscribe !" modals
- it often repeats content
- it inflates token usage like it’s training for a marathon
So the safer pattern is to convert HTML into clean markdown locally:
- strip obvious noise elements
- pull the "main content" using readability-style extraction
-
fall back to
< main>/< article>/ body when needed - convert to markdown with consistent formatting
- enforce a minimum "useful" length to avoid summarizing empty pages
This is the cost-saving heart of the system: do the messy cleanup without paying LLM token prices for garbage.
Step 4: "But Wait, The Web Is Hostile Now" (Anti-bot Measures)
Let’s pretend you wrote the perfect extractor. You still have a problem:
More and more sites do not want your scripts reading their pages.
You’ll see:
- 403s
- 429s
- "unusual traffic detected"
- "verify you are human" pages (which are ironically optimized for robots)
Problem #6Direct fetching fails more often than you’d like
So the fetching strategy should become:
- Try a direct origin fetch first (fast, cheapest).
- If it fails, try proxy routes (slower, costs money, but often works).
- If it still fails, mark the source as unusable and move on.
The key is that proxy usage should be a fallback, not the default. Proxies are like taxis: extremely useful, but you do not want to take one to walk across the street.
Also: not all content types should be treated equally. For example, PDF proxying can be enabled explicitly rather than always-on (because downloading large binaries through proxies is a special kind of fun you didn’t ask for).
Step 5: "Now We Have Content. Still Can’t Just Shove It Into An LLM."
At this point we’ve got markdown for a bunch of sources. We still don’t want to do the naive thing:
txtHere are 25 sources of markdown. Please produce a report.
That can work… but it’s brittle and expensive, and you lose control over what was extracted versus what was inferred.
Problem #7You need structure, not vibes
So instead, the safer approach is to ask the LLM to extract structured notes per source:
- title
- dense summary
- key facts
- important numbers (with units/dates)
- claims
- assumptions
- bias signals
- missing info
- related URLs (for expansion)
- related search queries (for expansion)
- confidence rating (High/Medium/Low)
Two important details make this practical:
- The output format is constrained to JSON (inside a fenced block), so it’s parseable.
- The code treats "malformed output" as a recoverable error and keeps going.
This step is the difference between a "summary generator" and a "research agent." Summaries are vibes. Notes are evidence.
Step 6: "We Need More Sources" (Recursive Expansion Without Spiraling)
Now comes the part that makes it "deep research" instead of "search-and-summarize":
From each good source, we extract:
⌗ Step 6
- a small set of related URLs to follow
- a small set of new search queries that fill gaps
Then we repeat, depth by depth.
Problem #8Recursion is how you accidentally invent a web crawler
If you expand without guardrails, you’ll end up:
- crawling the entire internet
- repeatedly re-fetching the same things
- burning time and budget
- producing a report that cites 200 sources but explains nothing
So hard caps are needed:
- maximum depth
- maximum sources per depth
- limits per source (related URLs / related queries)
- minimum "useful markdown" length
- dedupe everything, always
This creates a controlled exploration: it spreads wide, but it does not spiral into chaos.
Problem #8.5LLMs invent "related URLs" more often than you want
Even after per-source extraction is working, one ugly problem remains: the model will sometimes suggest URLs that look plausible but are brittle, stale, malformed, or simply hallucinated.
That creates a bad downstream loop:
- the crawler wastes retries on dead links
- PDFs get referenced through unstable download URLs
- DOI variants, arXiv PDF links, and canonical landing pages get mixed together
- the recursive crawl starts following model guesses instead of source evidence
- visited-URL dedup breaks down because the same paper shows up as three different URLs
So related-URL expansion needs another guardrail: only follow URLs that are actually present in the extracted source content, or a deterministic canonical form of one that is.
In practice, that means:
- extract observed URLs from the source markdown
- normalize and canonicalize them (strip tracking, resolve DOI/arXiv variants, unify YouTube/Reddit/GitHub URL shapes, and optionally, drop SERPs and paywall hosts entirely)
- reject anything the model invented that the source never actually linked
The canonicalization step does real work here — a source might link to
an arXiv PDF, a dx.doi.org redirect, and an
ar5iv.org render of the same paper. Without it, all three
get crawled and cited separately. With it, they collapse to one
arxiv.org/abs/ URL and the visited-set correctly suppresses
the duplicates.
The rule is simple: if it wasn't in the source, don' t follow it. The model's URL suggestions are a starting point for query expansion, not a crawl frontier.
Step 7: "Images Exist, and Sometimes They’re the Whole Point"
The web loves to put the important content in:
⌗ Step 7
- charts
- tables rendered as images
- screenshots
- infographics
If you ignore images, you’ll miss exactly the information someone cared about.
Problem #9You can’t send 50 images to a model and pretend it’s fine
So image understanding should be:
- optional (configurable)
- bounded (max images per page)
- concurrency-limited
- size-limited (skip enormous images)
- embedded back into the page markdown as a quoted "Image Description" block
This is a useful compromise:
- downstream extraction sees the image content as text
- you don’t explode token usage
- you avoid turning "research" into "download the entire CDN"
Also, images are fetched directly (no proxy routing for images), because image fetching is a slippery slope that can turn your networking layer into a thriller novel.
Step 8: Make the Final Report… Without Losing Citation Integrity
After per-source notes have been collected, the next challenge is synthesis. This is where a lot of systems quietly become unreliable:
⌗ Step 8
- citations drift
- references are incomplete
- the table of contents breaks
- you get
[12]in the text but no reference 12
Problem #10If everything is sent to the model at once, it forgets things
Once the source set gets large, a single giant "write the report" prompt starts causing familiar failures:
- important evidence disappears
- niche but relevant details get flattened away
- citation coverage drops
- the model condenses too aggressively because the input context is huge
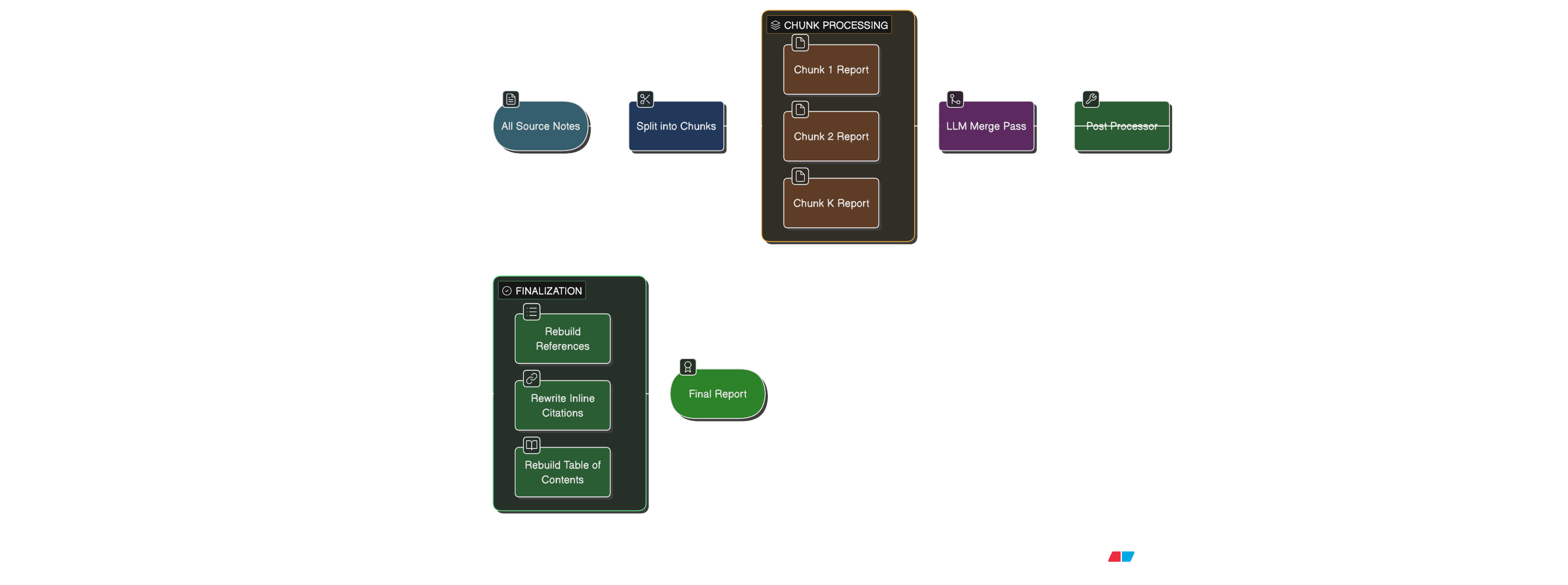
So instead of doing one monolithic final-report pass, it is safer to use a two-stage synthesis flow:
- Split the collected sources into
Nchunks. - Generate a detailed intermediate report for each chunk, keeping the original source citation numbers intact.
- Merge those intermediate reports into the actual final report.
This does two useful things:
- each chunk synthesis can pay attention to a smaller, more coherent dossier
- the final merge step works over higher-signal intermediate reports rather than a giant wall of raw source notes
Problem #11Chunking is only useful if citation integrity survives it
Chunked synthesis sounds nice until citations drift.
If chunk 2 renumbers its local sources from [1] to
[8], or if the final merge invents references that do not
map cleanly back to the original source list, the whole thing becomes
unreliable.
So the safer rule is: keep the original global source numbers all the way through the chunk reports and into the final report. Then rebuild the final references section deterministically from the full source list.
That means the post-processing step still matters:
- rebuild the references section deterministically from the source list
- rewrite inline citations into clickable anchor links
- rebuild the table of contents so the links actually work
This is unglamorous engineering, which is another way of saying: it is the part that makes the output feel like a product.
Step 9: Concurrency, Retries, and "Please Don’t Panic"
Real web research is mostly waiting for networks. So performance and resilience matter:
⌗ Step 9
- search requests run concurrently (bounded)
- fetch requests run concurrently (bounded, and usually higher than LLM concurrency)
- note extraction runs concurrently (bounded)
- intermediate chunk-report synthesis runs concurrently (bounded)
- everything has timeouts
- transient failures get retried with exponential backoff
The spirit here is:
- don’t make one bad website ruin the whole run
- don’t overload your own machine or APIs
- keep progress moving
Some failures are treated as "soft" (skip source, continue). A few are "hard" (for example: you can’t generate a report if you extracted zero usable sources).
A Quick Tour of "Stuck Moments" (And How We Unstuck Them)
If a deep-research build had a subtitle, it would be:
"How many edge cases can fit inside a simple idea?"
Here’s the sequence of pain, in order:
- "Let’s summarize a few URLs."
- "But the URLs are too few. We need broader coverage."
- "But now we have lots of URLs. Some are duplicates and tracking junk."
- "But now the HTML is massive and mostly noise."
- "But some URLs are PDFs and behave differently."
- "But some sites block direct fetching."
- "But proxies cost money; we can’t use them everywhere."
- "But the important information is sometimes inside images."
- "But image understanding can also cost money; it must be bounded."
- "But now citations and references need to be consistent and clickable."
- "But the model is losing detail because the final synthesis prompt is too big."
- "But chunking the synthesis will break things unless citation numbers stay stable."
A deep-research agent is not "one clever prompt." It is a pipeline of small, defensive decisions that keep the system stable, affordable, and honest.
Sample Reports
Below are outputs from a few runs of this deep-research agent:
| Report | Sources used | Max depth | Time (mm:ss) | Approx cost (USD) |
|---|---|---|---|---|
| What Happens If Compute Becomes a Sovereign Reserve Asset? | 38 | 2 | 22:40 | 0.06 |
| The Financialization of Compute Futures | 44 | 2 | 24:15 | 0.08 |
| The Coming "Power Wars" Between Humans and Datacenters: Rising Costs, Grid Strain, and the Battle for Electricity | 54 | 2 | 30:32 | 0.09 |
Note: these pages were generated from prepared markdown files to showcase on web.
The exact numbers can vary wildly based on:
- which sites block you (proxy fallbacks change the game)
- whether image descriptions are enabled
- how many sources are actually usable (thin/blocked pages get skipped)
- model choice for extraction vs synthesis
What Is Still Missing?
Even with all of this working, there are still several obvious ways to make the system better. A deep-research agent is never really “done”; it just becomes more useful as its memory, verification, and planning layers improve.
Future Improvements
- Better source quality scoring — not all sources deserve equal weight. Primary sources, filings, official docs, academic papers, and original datasets should be ranked differently from SEO blogs or recycled summaries.
- Claim-level citation checking — after the final report is written, a separate pass could verify whether every important claim is actually supported by the cited source.
- Contradiction detection — when sources disagree, the system should surface that disagreement instead of smoothing it into one confident-looking paragraph.
- Persistent research memory — related runs could reuse previously discovered sources, extracted notes, canonical URLs, and known source-quality signals instead of starting from zero each time.
- Better planning before crawling — the agent could first create a research map: what needs background, what needs recent news, what needs primary evidence, and what needs expert commentary.
- Human-in-the-loop checkpoints — for expensive or long research runs, the system could pause after planning or source discovery and ask which direction is actually worth pursuing.
- Stronger PDF and table extraction — many serious sources hide useful data inside reports, annexures, tables, charts, and scanned documents. Handling those well would improve report quality a lot.
- Evaluation runs — the system needs benchmark topics, expected facts, citation audits, and regression tests so changes improve quality instead of just making the pipeline more complicated.
The most interesting next step is probably not “make the model smarter.” It is making the surrounding system more disciplined: better source selection, better verification, better memory, and better ways to notice when the answer is uncertain.
In other words, the agent should become less like a fast summarizer and more like a careful researcher with a notebook, a checklist, and a healthy fear of being confidently wrong.
Closing Thoughts: It Looked Simple, Then It Wasn’t
Building a system like this is a reminder that "research" is a system problem:
From above, it looks like "search + summarize." Up close, it’s:
This started as a fun exercise — mostly curiosity, partly frustration with existing rate limits, and a simple question: what would it actually take to build one of these myself?
More than anything, though, it was genuinely rewarding. There is something deeply satisfying about taking an idea that looks simple from the outside, wrestling with all its ugly edge cases, and slowly turning it into something that actually works.
Source code will be published on GitHub in a few days. It needs a bit of refactoring, cleanup, removal of many temp files and hopefully a bit more to make it better (mostly around claim level citations and contradiction detection).
Thanks for Reading :)